Определение требований к производительности и емкости для сред совместной работы отделов (sharepoint server 2013)
Содержание:
- Введение
- Резюме файла RPS
- Не забываем
- Подбор размера пула в сервисе
- С чего начинали нагрузочное тестирование в Miro
- Устранение неполадок
- С какими препятствиями столкнулись при развитии нагрузочного тестирования в Miro
- Результаты внедрения нагрузочного тестирования в Miro
- Распределённая команда нагрузочного тестирования в Miro
- Что нужно для нагрузочного тестирования?
- Глоссарий
- Масштабируем базу по диску
- Этапы нагрузочного тестирования
- Тестовые данные — это важно
- Архитектура решения
- Все определения RPS
- Что означает RPS в тексте
- Планы в отношении нагрузочного тестирования в Miro
- Разница результатов открытого и закрытого тестов
- Масштабируем базу по памяти
Введение
В этой статье описано, как выполнять горизонтальное масштабирование серверов в решении для совместной работы отделов на основе SharePoint Server 2013. Решение для совместной работы отделов это развертывание SharePoint Server 2013, в котором для совместной работы используется меньшее количество компьютеров, чем в корпоративном решении для совместной работы. В этой статье предполагается, что отдел это организация внутри предприятия, в которой работает от 1000 до 10000 сотрудников.
При использовании различных сценариев возникают различные требования. Поэтому необходимо не только использовать сведения, содержащиеся в данном руководстве, но и проводить дополнительное тестирование конкретного оборудования в конкретной среде. Если планируемая структура и рабочие нагрузки аналогичны параметрам описанной в этой статье среды, вы можете определить ожидаемую производительность при горизонтальном и вертикальном масштабировании вашей среды.
Важно!
Результаты тестов, описанные в этой статье, получены в лаборатории тестирования, в которой для имитации рабочей среды в высококонтролируемых условиях использовались рабочая нагрузка, набор данных и архитектура. Несмотря на тщательную разработку этих тестов характеристики производительности лаборатории тестирования никогда не будут такими же, как у рабочей среды. Эти результаты не отражают характеристики производительность и емкость рабочей фермы. Результаты тестов всего лишь демонстрируют наблюдаемые тенденции пропускной способности, задержки и потребности в оборудовании. Используйте анализ наблюдаемых данных для планирования емкости и управления собственной фермой.
В этой статье содержится следующая информация.
-
Спецификации, включающие сведения об оборудовании, топологии и конфигурации.
-
Рабочая нагрузка, которая включает анализ потребностей фермы, числа пользователей и характеристик использования
-
Сведения о наборе данных, например о размерах баз данных и типах контента.
-
Результаты тестов и их анализ для горизонтального масштабирования веб-серверов.
Резюме файла RPS
У нас есть один существующие программные обеспечения, связанные с файлами RPS (как правило это программное обеспечение от Autodesk, Inc., известное как Autodesk 3ds Max), и их можно отнести к категории основных типов файлов один. Традиционно эти файлы имеют формат 3ds Max Render Preset Settings .
В большинстве случаев эти файлы относятся к Settings Files.
Файлы RPS можно просматривать с помощью операционной системы Windows. Они обычно находятся на настольных компьютерах (и ряде мобильных устройств) и позволяют просматривать и иногда редактировать эти файлы.
Рейтинг популярности данных файлов составляет «Низкий», что означает, что они не очень распространены.
Не забываем
Закрывать результат
Это обсуждали множество раз, но тем не менее. Даже если в документации к библиотеке написано, что , лучше всё же закрыть самому через defer.
Как только внутри цикла по rows.Next() случится паника или мы сами добавим туда выход из цикла — rows останется незакрытым. Незакрытый результат — это соединение, которое не может быть использовано другими запросами, но занимает место в пуле. Его придется убивать по таймауту и заменять на новое, а это долго.
Быстрые транзакции
Применительно к pgbouncer: медленные транзакции забивают серверный пул.
Долгая транзакция вызывает те же проблемы, что и незакрытый результат: соединение невозможно использовать ни для чего другого.
Особенно опасны незакрытые транзакции, а это ошибка, которую в Go сделать довольно легко. Если pool_mode установлен в transaction, как это сделано у нас, то незакрытая транзакция надолго занимает собой соединение, в нашем случае на два часа.
Медленные же транзакции часто можно без больших затрат разделить на несколько быстрых. Если же это невозможно, то стоит подумать об отдельной реплике базы для них.
Keepalive
Keepalive — это фича, которую не стоит включать бездумно. Она полезна, когда входящих соединений мало, например, если к вам ходят другие ваши сервисы и вы можете контролировать, сколько соединений они создают. При бесконтрольном создании соединений под высокой нагрузкой у сервиса окажется множество незакрытых соединений. Каждое из них отъест свои 2-4 Кб, и будет плохо.
Проверять гипотезы практикой
В вопросах производительности запросто можно получить противоположный ожидаемому результат. Слишком много факторов вмешиваются в процесс. Любое своё предположение желательно проверять на железе и с цифрами.
Подбор размера пула в сервисе
Как мы увидели, ограничение размера пула сервиса оказывает весьма существенное влияние на производительность. К сожалению, часто пул не ограничивают вообще. Из-за этого сервис держит меньшую нагрузку, чем мог бы, возникают мистические таймауты под штатной нагрузкой, а в некоторых случаях может серьёзно деградировать производительность базы данных.
Общее число соединений есть смысл выбирать в интервале от числа ядер, доступных базе, до ограничения на число серверных соединений у pgbouncer (каким его выбрать — вопрос для DBA).
При числе соединений меньше числа ядер база остаётся незагруженной, т.к. в Постгресе каждое соединение обслуживается отдельным процессом, который максимум может нагрузить одно ядро. Если соединений больше, чем максимальное число серверных соединений, начнётся мультиплексирование.
Конечно, эти соображения пригодны, когда нет долгих транзакций и медленных выборок из базы, которые надолго занимают соединение. Если они у вас есть, стоит подумать, как от них избавиться. Кроме того, опасно именно переключение соединений под нагрузкой. Задачи, работающие в разное время, например, сервис с пиковым трафиком днем и ночной крон, могут использовать полный пул каждая: мультиплексирования будет немного.
С чего начинали нагрузочное тестирование в Miro
- Несколько человек занимались НТ часть своего времени.
- Мы использовали JMeter как наиболее популярное решение. У нас был свой плагин для WebSocket, так как ключевой функционал Miro связан с работой с досками и требует очень быстрого клиент-серверного взаимодействия, как в играх. Кстати движок, с которого много лет назад начинала компания, был как раз игровым. Это с самого начала дало высокую интерактивность и скорость отклика.
- Наш кластер был prod-like. К счастью, у нас был IaC. Нельзя сказать, что IaC — это серебряная пуля, сложности с ним тоже есть, но без него сложности с ростом масштаба становятся фатальными препятствиями.
- Один достаточно объёмный и сложный WebSocket&HTTP API тест.
Устранение неполадок
Типичные проблемы открытия RPS
Autodesk 3ds Max нет
Вы пытаетесь загрузить RPS-файл и получить сообщение об ошибке, например «%%os%% не удается открыть расширение файла RPS». Как правило, это происходит в %%os%%, поскольку Autodesk 3ds Max не установлен на вашем компьютере. Поскольку ваша операционная система не знает, что делать с этим файлом, вы не сможете открыть его двойным щелчком мыши.
Совет: Если у вас есть другое программное обеспечение, которое вы знаете, открывает файлы RPS, вы можете выбрать его, нажав кнопку «Показать приложения».
Устаревшая версия Autodesk 3ds Max
В некоторых случаях может быть более новая (или более старая) версия файла 3ds Max Render Preset Settings, которая не поддерживается установленной версией приложения. Если у вас нет правильной версии Autodesk 3ds Max (или любой из других программ, перечисленных выше), вам может потребоваться попробовать загрузить другую версию или одно из других программных приложений, перечисленных выше. Ваш файл электронной таблицы, вероятно, был создан более новой версией Autodesk 3ds Max, чем то, что в данный момент установлен на вашем компьютере.
Совет . Если щелкнуть правой кнопкой мыши файл RPS, а затем выбрать «Свойства» (Windows) или «Получить информацию» (Mac), вы можете получить подсказки о том, какая версия вам нужна.
Сводка. Наличие правильной версии Autodesk 3ds Max на компьютере может вызвать проблемы с открытием RPS-файлов.
Хотя на вашем компьютере уже может быть установлено Autodesk 3ds Max или другое программное обеспечение, связанное с RPS, вы по-прежнему можете столкнуться с проблемами при открытии файлов 3ds Max Render Preset Settings. В %%os%% могут возникать внешние проблемы, которые вызывают эти ошибки при открытии RPS-файлов. Проблемы, которые не связаны с программным обеспечением:
С какими препятствиями столкнулись при развитии нагрузочного тестирования в Miro
- JMeter перестал нас устраивать. В нём было очень неудобно программировать и отлаживать. Сложные сценарии — это почти всегда разработка, а не заполнение форм или написание отдельных небольших скриптов. Сценарий в JMeter — это не программа в обычном понимании, а сочетание инструкций, заполненных в формах, с встроенным кодом скриптов. Также в JMeter плохо с контролем версий, т.к. сценарий хранится в огромном XML. А у нас большое количество WebSocket взаимодействия со своим бинарным протоколом и достаточно сложные сценарии, над которыми работает несколько человек. Не хотелось изобретать обходные пути вокруг «особенностей» JMeter.
- Много ручных действий для каждого запуска НТ на тестовом окружении. TODO лист состоял из 16 пунктов для каждого запуска, которые надо было проделывать вручную… И это была боль… А боль — это сильный стимул что-то поменять.
- Не хватало инструментов для генерации разных распределений тестовых данных. А сценарии тестирования для разных компонентов возможны разные и нужно было уметь быстро создать нужное распределение. Идеально использовать базу максимально близкую проду и откатывать после каждого теста, но не всегда это возможно: это могут быть огромные объёмы и надо чистить сенситивные данные пользователей, а воспроизводить синтетические данные в нужном объёме — тоже сложная задача.
- Много задач.
- Недостаточно опыта.
- Недостаточно доступных людей.
Результаты внедрения нагрузочного тестирования в Miro
- Понятный и описанный процесс. Чётко описано, какие шаги нужно выполнить и что нужно делать на каждом из шагов.
- Большие тесты: 200K, 500K пользователей online при типичном сценарии использования. Каждый сложный тест зачастую проходит много итераций перед успешным выполнением, поэтому без автоматизации столько раз гонять большие тесты было бы чрезвычайно долгим и утомительным занятием, полным ошибок.
- Проверка компонентов перед выкаткой на прод.
- Обоснованный выбор параметров компонентов для поддержки планируемой нагрузки. То есть не просто с потолка брать «ну наверное хватит сотни воркеров», а выбирать параметры на основе результатов проверок.
- Автоматизация, упрощение и ускорение проведения НТ. Я говорил в начале про список из 16 пунктов, которые надо было пройти вручную при каждом запуске НТ на кластере. Теперь это один конфиг и одна команда. Больше автоматизации даёт больше надёжности и больше возможностей уделить время более творческим и сложным задачам.
- Деградационное тестирование (начало). Автоматическое выполнение тестов по реалистичному API сценарию на типичной нагрузке каждую ночь на последней версии сервера и построение графиков трендов для отслеживания динамики показателей скорости ответа и числа ошибок.
Распределённая команда нагрузочного тестирования в Miro
«Центр» — команда НТ — центр компетенций и поддержки
Зоны ответственности:Разработка инструментария (особое внимание к качеству!). У функциональных команд заказчик — клиенты Miro, у нашей команды заказчик — функциональные команды
Внутренние инструменты не должны быть поделками, сделанными «на коленке». Это должны быть полноценные и качественные продукты с должным уровнем поддержки всех видов. Функциональные команды и так загружены и повышать их уровень стресса плохими инструментами — недопустимо. Поэтому у нас есть:Мастер-классы.
Miro доски-презентации.
Confluence документация.
Версии, changelog, детальная отладочная информация в ходе работы инструмента.
Общий репозиторий с примерами кода и всеми НТ сценариями, чтобы было единое место, где собрана вся практика НТ.
Отдельные чаты на каждый инструмент для поддержки, сообщений о релизах, багрепортов и фичереквестов.
Помощь в обучении и консультирование коллег из функциональных команд, не только QA инженеров.
Проведение больших тестов, когда нужна проверка суммы функционала от множества команд.
Поддержка тестовых окружений совместно с QA Automation Team и DevOps Team.
«Агенты» — QA инженеры и разработчики в функциональных командах — проводят более узконаправленные тесты.
Что нужно для нагрузочного тестирования?
- Общие требования. Нам нужно понимать, чего мы ожидаем от нашей системы в контексте нагрузки и производительности, хотя бы в общих чертах. Это может звучать просто, но не всегда у людей есть ясное представление о таких требованиях. «Система должна отвечать быстро под высокой нагрузкой» — это не требование, это пожелание. Я покажу примеры удачнее дальше в статье.
- Специалисты. Для проведения НТ нужны инженеры. Поскольку серьёзное тестирование всегда требует автоматизации, нужны инженеры с навыками тестирования и разработки, а также аналитики и девопсы.
- Платформа для тестового окружения. Если вы делаете НТ в первый раз — вам определённо понадобится подготовить инфраструктуру. Хорошо если у вас внедрён подход IaC (англ. infrastructure as a code, инфраструктура как код), он очень пригодится для создания окружения, подобного проду. Если нет — надо внедрять или придётся страдать даже на небольших конфигурациях. И в подавляющем большинстве случаев тестирование на проде — плохая идея. Но есть и исключения, можете погуглить «Netflix testing in production».
- Время. НТ — это очень затратный по времени процесс, особенно когда вы делаете его впервые. Автоматизация экономит много времени, но всё равно нужно быть готовым потратить на подготовку и проведение НТ несколько дней или существенно больше, зависит от масштабов прода, используемого стэка, сценариев использования и поставленных задач.
Глоссарий
В списке ниже представлены определения ключевых терминов, используемых в этой статье.
-
RPS. Количество запросов в секунду. RPS это количество запросов, получаемых фермой или сервером за одну секунду. Это общепринятая единица измерения нагрузки на сервер или ферму.
Примечание
Запросы и загрузки страниц это не одно и то же. Страница содержит несколько компонентов, каждый из которых создает один или несколько запросов при загрузке страницы браузером. При загрузке одной страницы создается несколько запросов. Обычно процедуры проверки подлинности и события, использующие незначительное количество ресурсов, не учитываются при измерениях RPS.
-
Зеленая зона. Зеленая зона представляет собой заданный набор характеристик нагрузки в нормальных условиях работы (до прогнозируемых ежедневных пиковых нагрузок). Ферма, работающая в этом диапазоне, должна быть способна поддерживать время ответа и задержки в рамках допустимых параметров.
Это состояние, в котором сервер удовлетворяет указанным ниже условиям.
-
Задержка на стороне сервера для не менее чем 75 % запросов составляет менее одной секунды.
-
Уровень использования ЦП на всех серверах фермы не превышает 60 %.
Примечание
Наша лабораторная среда не имеет активного запущенного обхода контента при поиске, поэтому мы поддерживали использование ЦП на сервере базы данных на уровне, не превышающем 50 %, чтобы зарезервировать 10 % для нагрузки обхода контента при поиске. При этом предполагается, что для ограничения нагрузки обхода контента при поиске на уровне 10 % в рабочей среде используется регулятор ресурсов SQL Server.
-
Процент сбоев составляет менее 0,01 %.
-
-
Красная зона (макс.) Красная зона представляет определенный набор характеристик нагрузки в пиковых условиях работы. В красной зоне для фермы характерна временная повышенная потребность в ресурсах, при которой работа может поддерживаться только в течение ограниченного периода, пока не наступит отказ или не возникнут иные проблемы, связанные с производительностью и надежностью.
Это состояние, в котором сервер удовлетворяет указанным ниже условиям в течение ограниченного периода времени.
-
Компонент регулирования запросов HTTP включен, но ошибки 503 (сервер занят) отсутствуют.
-
Процент сбоев составляет менее 0,1 %.
-
Задержка на стороне сервера для не менее чем 75 % запросов составляет менее 3 секунд.
-
Уровень использования ЦП на всех серверах фермы (кроме серверов баз данных) не превышает примерно 90 %.
-
Использование ЦП сервера базы данных не превышает примерно 50 %, что позволяет иметь достаточный резерв для нагрузки обхода контента при поиске.
-
-
AxBxC (примечание к графику). Это, соответственно, число веб-серверов, серверов приложений и серверов баз данных в ферме. Например, значение 10x1x1 указывает на то, что в данной среде имеется 10 веб-серверов, 1 сервер приложений и 1 сервер базы данных.
-
MDF и LDF: SQL Server физические файлы. Дополнительные сведения см. в материалах Files and Filegroups Architecture.
Масштабируем базу по диску
Проверим, является ли узким местом диск. Увеличиваем квоту контейнера в 8 раз, смотрим:
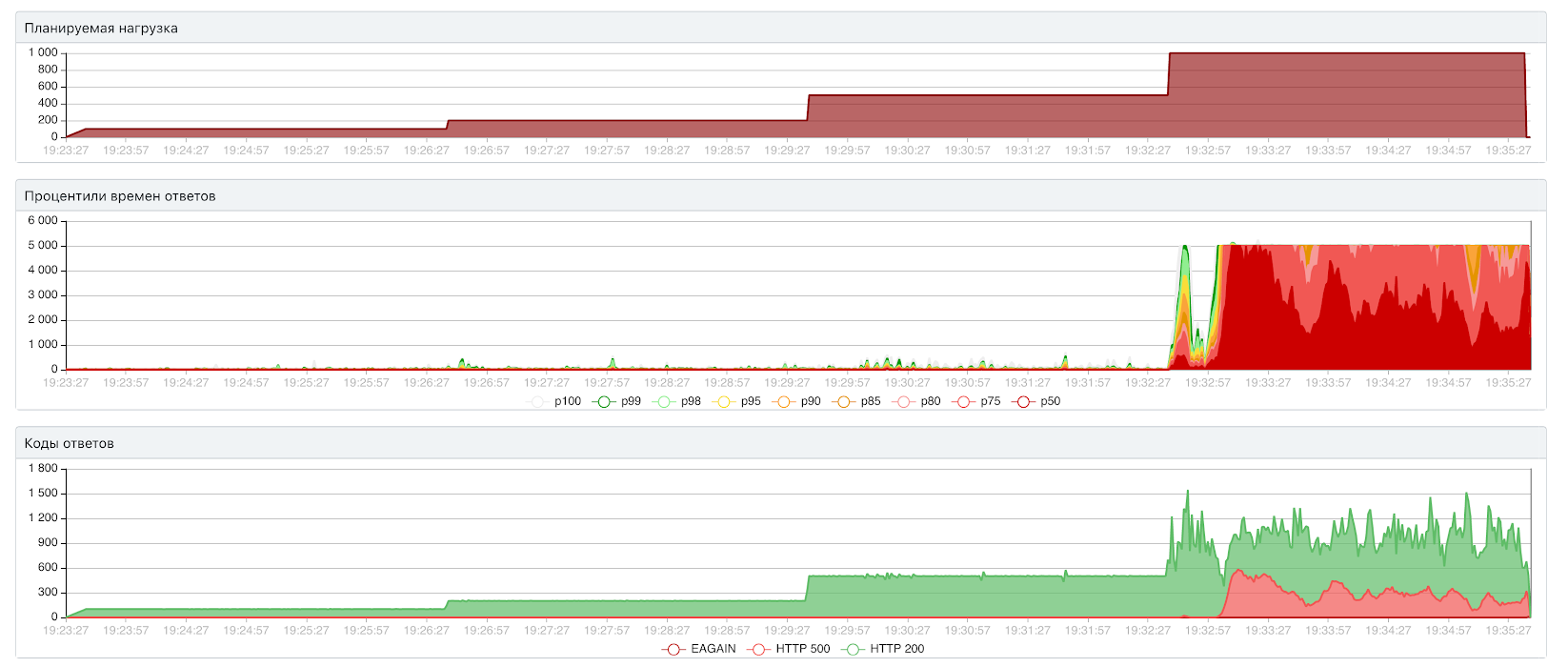 Открытый тест: 500 RPS / 109 мс
Открытый тест: 500 RPS / 109 мс
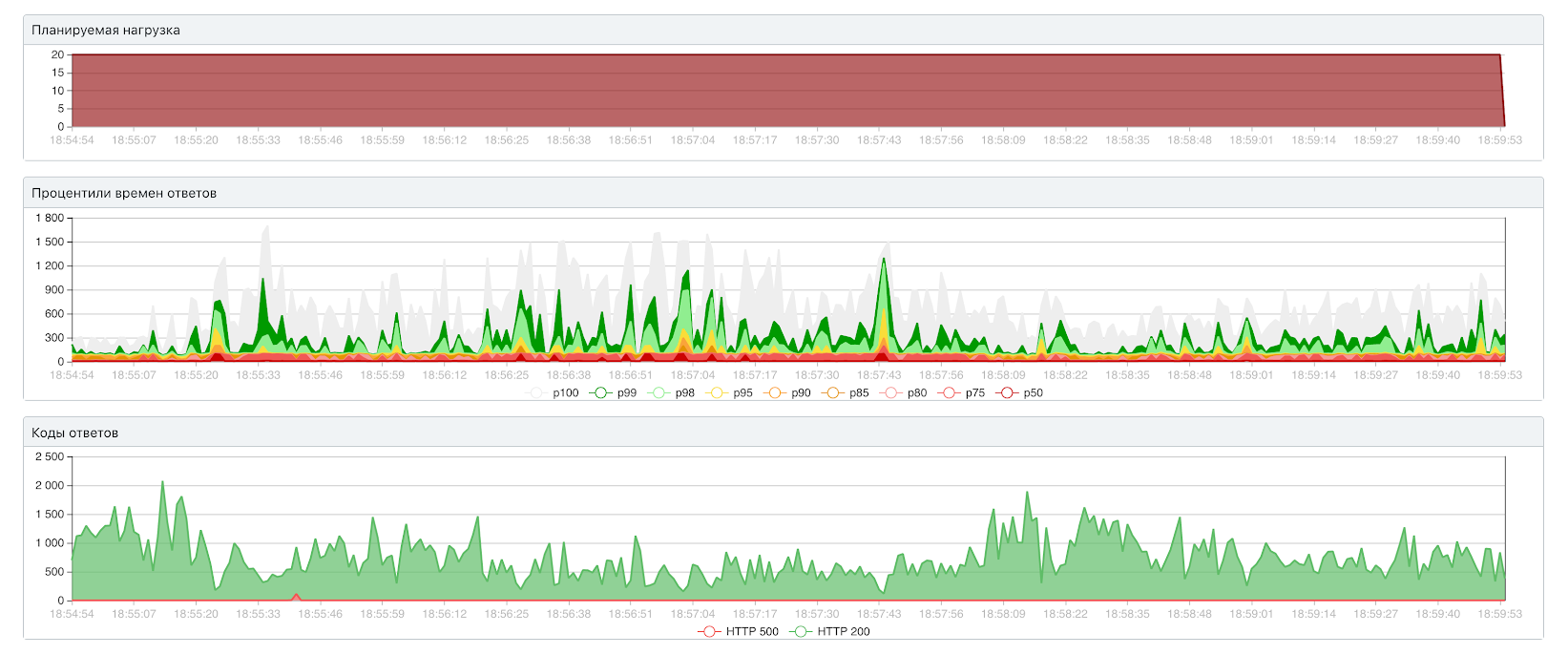 Закрытый тест: 745 RPS
Закрытый тест: 745 RPS
В закрытом тесте пропускная способность выросла со 130 RPS до 745 — почти линейный рост. Значит, мы действительно упираемся в диск.
Оценим предел вертикального масштабирования. Снимаем с контейнера ограничение на операции ввода-вывода вообще:
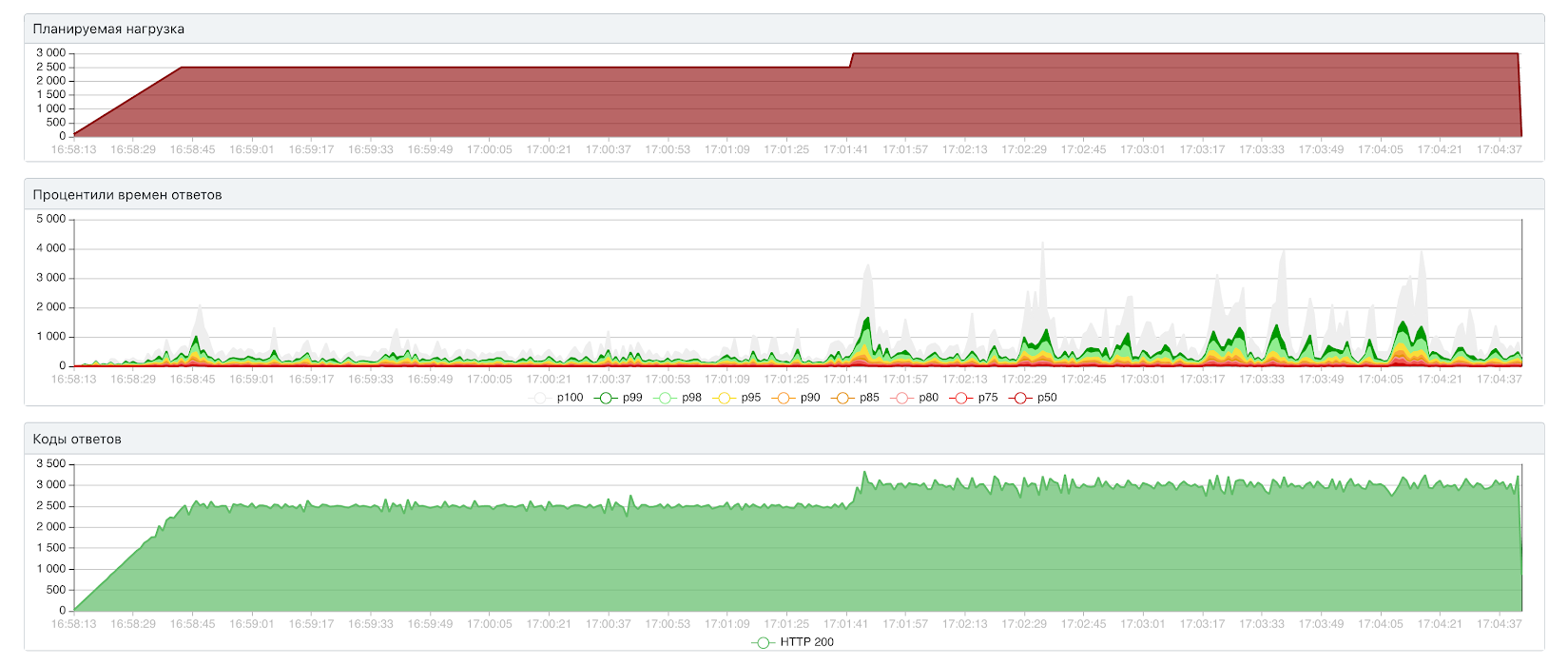 Открытый тест: 3000 RPS / 602 мс
Открытый тест: 3000 RPS / 602 мс
 Закрытый тест (20 инстансов): 2980 RPS / 62 мс
Закрытый тест (20 инстансов): 2980 RPS / 62 мс
Заметим, что закрытому тесту явно не хватает 20 параллельных запросов, чтобы нагрузить сервис. Мы съели вообще весь диск на всём сервере с базой:
 Зелёное — число операций чтения (растёт вниз)
Зелёное — число операций чтения (растёт вниз)
Конечно, в продакшене так себя вести нельзя: придут злые девопсы и будут нас ругать. Вообще, упираться в диск очень не хочется: его сложно масштабировать, мы будем мешать соседям по серверу, а они будут мешать нам.
Попытаемся уместить данные в память, чтобы диск перестал быть узким местом.
Этапы нагрузочного тестирования
- Детализация требований — что требуется от системы в терминах нагрузки и производительности, какой тип теста проводим и какие метрики необходимо собрать для проверки требований. Как я писал ранее, общие требования нужны ещё до тестирования, а когда процесс начат, нужно их декомпозировать в предельно конкретные и технические требования. Также нужно выбрать тип теста, реализуемого в тестовом сценарии, и составить список метрик, на сбор которых нужно настроить приложение, сценарий и инфраструктуру. Это аналитическая задача.
- Подготовка тестового окружения — где будем моделировать прод и пользователей. Необходимо выбрать одно из доступных или создать новое тестовое окружение под разработанные требования и настроить сбор метрик, нужных для оценки степени соответствия требованиям. Это задача DevOps специалистов.
- Выбор инструмента тестирования и подготовка сценария — как будем моделировать поведение пользователей. В сценарии тоже нужно запрограммировать сбор метрик. Это задача разработки.
- Проведение теста и замеры — каковы значения метрик. Это может звучать просто, но весьма редко всё работает с первого раза. Бывает нужно откатиться на один из предыдущих шагов и что-то поправить. На данном этапе проводится анализ некоторых ключевых показателей, чтобы убедиться, что нет критических ошибок теста. Этот шаг — задача тестирования. Основная работа по анализу будет вестись на следующем этапе.
- Анализ — соответствует ли система требованиям, есть ли проблемы. Если собираются правильные метрики, всё должно быть относительно просто, хотя и трудоёмко, а если нет — опять может понадобиться откатиться вплоть до первого шага. Здесь, в отличие от предыдущего шага, мы глубоко погружаемся в большое количество метрик чтобы выявить все возможные значимые факты. Это аналитическая задача.
- Подготовка отчёта — какие знания мы получили?.. Это самый важный этап. НТ — процесс очень затратный по ресурсам и вы явно захотите получить максимум знаний от него. Снова аналитическая задача.
Тестовые данные — это важно
Мы старались по максимуму использовать реальные данные. Использовали их, где получалось, для наполнения базы, добавив шум. Для создания ленты запросов собрали реальные запросы с прода. Где это было невозможно, использовали генератор. Было ясно, что любые предположения, не основанные на реальных данных, будут снижать надёжность результатов тестов.
Изначально мы использовали ленту в 20 тысяч запросов. И довольно быстро удалось добиться такого результата:

Тут сервис держит 1000 RPS при 52.5 мс. Всё красиво, кроме скачков времени отклика, но давайте попробуем потестировать ту же конфигурацию на ленте в 150 тысяч запросов:

Уже на 200 RPS сервис заваливается. Запросы отваливаются по таймауту, появляются 500-ки. Оказывается, предыдущий тест врёт примерно в 10 раз по пропускной способности.
Похоже, для ленты в 20 тысяч запросов использовалась лишь часть данных в таблицах. PostgreSQL смог всё закэшировать и работал быстро. Для ленты в 150 тысяч требовалось больше данных из таблиц, в кэш они не поместились, и быстродействие упало.
Получается, не уделив достаточно внимания входным данным, легко испортить всё нагрузочное тестирование.
Архитектура решения
Искать подходящие отделения и считать цены доставки будем на бэкенде. Для повышения надёжности и по юридическим причинам тарифы и методику расчёта цены доставки мы хотим хранить у себя, а не ходить за ценой к подрядчикам. Тарифы будем хранить в унифицированном виде для всех служб доставки.
Для расчёта цены используем отдельный микросервис со своим хранилищем.
В качестве хранилища мы рассматривали Elasticsearch, MongoDB, Sphinx и PostgreSQL. По результатам исследования выбрали PostgreSQL: он закрывает наши потребности и при этом существенно проще в поддержке для нашей компании, your mileage may vary.
Налоги и комиссии в статье рассматривать не будем. Нас интересует только базовая цена доставки от подрядчика.
Все определения RPS
| Акроним | Определение |
|---|---|
| RPS | Raytheon Полярный услуги |
| RPS | Rulang начальная школа |
| RPS | Белгород начальная школа |
| RPS | Буровые установки продуктов и услуг |
| RPS | Быстрое первичного обследования |
| RPS | Возобновляемой Портфолио стандарт |
| RPS | Восстановить охраняемых видов |
| RPS | Вращение в секунду |
| RPS | Выбор поставщика ресурсов |
| RPS | Датчик давления железнодорожных |
| RPS | Датчик положения ротора |
| RPS | Датчик положения стойки |
| RPS | Доход на акцию |
| RPS | Железные дороги пенсионный план |
| RPS | Записи парламентов Шотландии 1707 |
| RPS | Записывает и издательские услуги |
| RPS | Запись и воспроизведение системы |
| RPS | Заявление о практике регистрации |
| RPS | Зондирование вращательных позиции |
| RPS | Избыточные защитные системы |
| RPS | Исследования, издательские услуги |
| RPS | Кольцо параметров сервера |
| RPS | Королевское фармацевтическое общество |
| RPS | Королевское филателистическое общество |
| RPS | Королевское фотографическое общество |
| RPS | Красный перец программное обеспечение компании |
| RPS | Набор обычных продуктов |
| RPS | Надежный пассивный Сонар |
| RPS | Обзор и определение приоритетности Подкомитет |
| RPS | Оборотов в секунду |
| RPS | Общество почечной патологии |
| RPS | Общество производителей каучука |
| RPS | Ограниченных ресурсов |
| RPS | Относительный фазовый сдвиг |
| RPS | Пенсионные Планирование семинара |
| RPS | Пенсионный план обслуживания |
| RPS | Повторяющиеся платежной системы |
| RPS | Почечных прессорных веществ |
| RPS | Предложение удаленной системы |
| RPS | Проезжую часть пакета услуг |
| RPS | Психо социальных рисков |
| RPS | Радиационной защиты стандарта |
| RPS | Радиоизотопные энергосистемы |
| RPS | Радиолокационные позиции символа |
| RPS | Радужный портал программного обеспечения |
| RPS | Раппорт-де-Preliminaire служба безопасности |
| RPS | Растровый стандарт продукта |
| RPS | Реактивный полистирол |
| RPS | Реальные лица слэш |
| RPS | Редич филателистическое общество |
| RPS | Резервный источник питания |
| RPS | Ремонт программное обеспечение программы |
| RPS | Рентген в секунду |
| RPS | Решения для возобновляемых источников энергии |
| RPS | Рибосомных белков |
| RPS | Ричмонд государственные школы |
| RPS | Роботизированная пациента тренажеры |
| RPS | Розанна начальная школа |
| RPS | Рок ножницы бумага |
| RPS | Рок, бумага, ружье |
| RPS | Рокфорд государственные школы |
| RPS | Роль играет моделирование |
| RPS | Роль играет стратегия |
| RPS | Руководитель радиационной защиты |
| RPS | Система играет роль |
| RPS | Система координат точки |
| RPS | Система обработки денежных |
| RPS | Система планирования разведки |
| RPS | Система программирования в реальном времени |
| RPS | Система роботизированной прекурсоров |
| RPS | Система удаленного питания |
| RPS | Системы зарегистрированные публикации |
| RPS | Системы защиты реактора |
| RPS | Случайные предустановленной подмножеств |
| RPS | Ссылка фото выбор |
| RPS | Станция удаленной обработки |
| RPS | Стойки & шестерня рулевого |
| RPS | Студия керамики палисандр |
| RPS | Схема крепления Цена |
| RPS | Удаленная система планирования |
| RPS | Услуга предоставления запасных частей |
| RPS | Услуги недвижимости |
| RPS | предписано позитронная спектроскопия |
Что означает RPS в тексте
В общем, RPS является аббревиатурой или аббревиатурой, которая определяется простым языком. Эта страница иллюстрирует, как RPS используется в обмена сообщениями и чат-форумах, в дополнение к социальным сетям, таким как VK, Instagram, Whatsapp и Snapchat. Из приведенной выше таблицы, вы можете просмотреть все значения RPS: некоторые из них образовательные термины, другие медицинские термины, и даже компьютерные термины. Если вы знаете другое определение RPS, пожалуйста, свяжитесь с нами. Мы включим его во время следующего обновления нашей базы данных. Пожалуйста, имейте в информации, что некоторые из наших сокращений и их определения создаются нашими посетителями. Поэтому ваше предложение о новых аббревиатур приветствуется! В качестве возврата мы перевели аббревиатуру RPS на испанский, французский, китайский, португальский, русский и т.д. Далее можно прокрутить вниз и щелкнуть в меню языка, чтобы найти значения RPS на других 42 языках.
Планы в отношении нагрузочного тестирования в Miro
- Деградационное тестирование (полноценная интеграция с CI/CD). В идеале постоянное НТ должно быть встроено в пайплайн и так же как функциональные тесты влиять на принятие решения о релизе.
- Тестирование микросервисов. Мы в процессе переезда с монолита, и всё больше работы появляется в этом направлении.
- Вовлечение большего числа команд. У нас их несколько десятков и пока не все включены в процесс.
- Улучшение инструментария. При бурном росте не всегда получается выдержать хорошую архитектуру, так что есть немного техдолга.
- Дополнение внутренней документации НТ примерами конкретных кейсов: как тестировали, что и как выявили, как доработали. Общая документация — это хорошо, но дополнение её солидным набором описаний конкретных кейсов — бесценно.
- Более исследовательская работа: профилирование, хаос-тестинг и т.д.
Разница результатов открытого и закрытого тестов
Почему разница не заметна в закрытом тесте, у меня точного ответа нет, но есть рабочая гипотеза.
Судя по коду , pgbouncer не стремится любой ценой подключить соединение к серверному. Нашлось свободное серверное соединение — хорошо, подключим. Нет — придётся подождать. Этакая кооперативная многозадачность, в которой соединения не очень хотят кооперироваться.
Получается, активное клиентское соединение, в котором без остановки выполняются запросы, может довольно долго не освобождать серверное соединение. А запрос, попавший на неактивное соединение, будет долго ждать своей очереди.
Пока запросов в системе мало, как в закрытом тесте, это роли не играет: запросам хватает таймаута, чтобы дождаться своей очереди. В открытом тесте запросов в системе в разы больше, они выстраиваются в очередь на захват соединения в pgx и тратят там большую часть таймаута. На захват серверного соединения в pgbouncer времени не остается. Происходит таймаут и 500-я ошибка.
Но это лишь правдоподобные рассуждения, хорошо бы их проверить. Когда-нибудь потом.
Масштабируем базу по памяти
Смотрим размеры наших таблиц и индексов:
Видим 21 Гб данных и 6 Гб индексов. Это существенно больше полезного объёма данных, но тут Постгресу виднее.
Нужно подобрать конфигурацию базы, которая могла бы вместить 27 Гб в памяти. В Авито используются несколько типовых конфигураций PostgreSQL: они хорошо изучены, а параметры в них согласуются друг с другом. Никто не запрещает кастомизировать конфигурацию под потребности конкретного сервиса, но начинать лучше с одной из готовых конфигураций.
Смотрим список конфигураций и находим вот такую:
 8 ядер, 64 Гб памяти, effective_cache_size 48 Гб
8 ядер, 64 Гб памяти, effective_cache_size 48 Гб
effective_cache_size — это не настоящий размер кэша, это просто параметр планировщика, чтобы тот представлял, на сколько памяти ему рассчитывать. Можно здесь хоть петабайт поставить — размер кэша не увеличится. Просто планировщик будет предпочитать алгоритмы, которые хорошо работают с данными в памяти. Но всё же этот параметр в типовой конфигурации наши DBA выбрали не случайно: он учитывает разные кэши, доступные базе, в том числе кэш операционной системы. В общем, надо пробовать:
 Открытый тест: 4000 RPS / 165 мс
Открытый тест: 4000 RPS / 165 мс
 Закрытый тест (100 инстансов): 5440 RPS / 106 мс
Закрытый тест (100 инстансов): 5440 RPS / 106 мс
 Операции чтения (зелёное) — на нуле, операции записи (жёлтое) — в незначительных количествах
Операции чтения (зелёное) — на нуле, операции записи (жёлтое) — в незначительных количествах
Диск больше не является узким местом и, прямо скажем, бездельничает.
 Утилизация CPU — полностью загружены все 8 ядер
Утилизация CPU — полностью загружены все 8 ядер
Теперь мы упираемся в процессор. Это хорошо: масштабировать его относительно просто, а мешать мы никому не будем.
Единственное, что смущает, — большая разница в результатах открытого и закрытого тестов. Это может свидетельствовать о проблемах с соединениями. Смотрим метрики pgbouncer, и точно:

Опять cl_waiting подскочил. В этот раз, правда, cl_acitve (жёлтое) не падает, а cl_waiting (красные точки, правая шкала) не поднимается выше 12.
Ну, это просто ошибка в конфигурации базы. Размер пула должен быть 24, именно такой пул выставлен в сервисе. А на стороне базы он остался равным 12. Исправляем, смотрим:
 Открытый тест: 5000 RPS / 140 мс
Открытый тест: 5000 RPS / 140 мс
Закрытый тест (100 инстансов): 5440 RPS / 94 мс
Вот теперь хорошо. В закрытом тесте результаты те же, а вот в открытом пропускная способность выросла с 4000 до 5000 RPS. Стоит отметить, что нет никакого смысла использовать больше соединений, чем размер пула БД: это лишь портит производительность. Впрочем, это наблюдение заслуживает более пристального изучения.
